


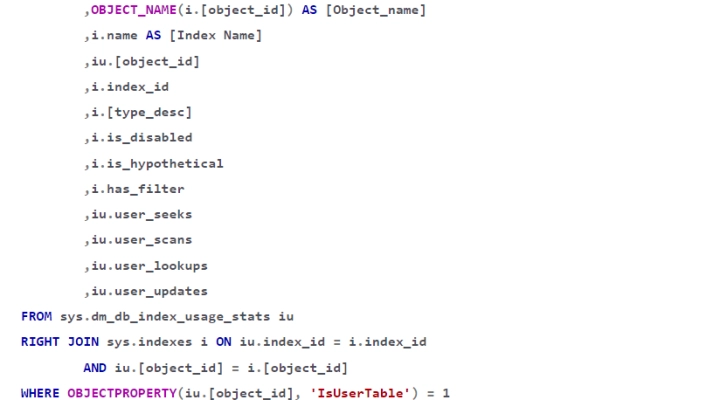
Gli indici di SQL Server sono essenzialmente copie dei dati già esistenti nella tabella, ordinati e filtrati in diversi modi per migliorare le prestazioni delle query eseguite.
Sebbene un uso corretto degli indici di SQL Server possa garantire prestazioni migliori per le query eseguite e quindi per SQL Server in generale, impostarli in modo improprio o non impostarli ove necessario, può peggiorare significativamente le prestazioni delle query. Inoltre, anche avere indici non necessari che non vengono utilizzati dalle query (definiti bad index) può essere problematico.
Gli indici di SQL Server sono infatti uno strumento eccellente per migliorare le prestazioni delle query SELECT, ma allo stesso tempo hanno effetti negativi sugli aggiornamenti dei dati. Gli indici inutilizzati nel tempo si accumulano nel database, spesso proprio perché sono stati creati per “una query specifica” e sono inutili in generale, o perché i cambiamenti nella distribuzione dei dati hanno portato l’Optmizer a cambiare la sua strategia. Questi indici comportano un sovraccarico su qualsiasi operazione di scrittura.
Le operazioni INSERT, UPDATE e DELETE provocano l'aggiornamento dell'indice e quindi la duplicazione dei dati già esistenti nella tabella. Di conseguenza, aumenta la durata delle transazioni e dell'esecuzione delle query e spesso possono verificarsi lock, block, deadlock e timeout di esecuzione abbastanza frequenti. Ciò si può anche tradurre in una frammentazione dell'indice e spesso si finisce per utilizzare ancora più risorse per eseguire ricostruzioni o riorganizzazioni di indici che vengono utilizzati raramente.
Per database o tabelle di grandi dimensioni, lo spazio di archiviazione è influenzato anche da indici ridondanti. Un obiettivo fondamentale, di qualsiasi DBA SQL Server, è dunque quello di mantenere gli indici inclusa la creazione di nuovi indici richiesti ma allo stesso tempo rimuovere quelli che non vengono utilizzati.
Fonte notizia
www.datamaze.it blogs post bad-index-eliminazione










